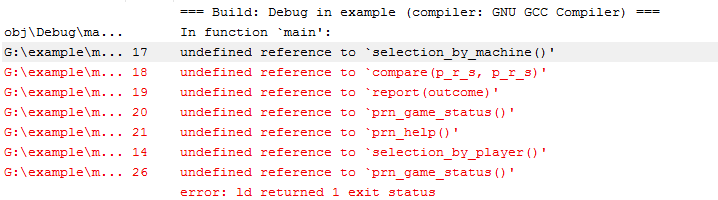
上海交大工科平台部分数据披露
2019年,上海交通大学工科平台(工科试验班)建设进入第5个年头。
2014级开始招第一届工科试验班,共有8个学院23个专业。
2015级软件工程、化学工程与工艺和核工程与核技术退出试验班专业名录。
2016级取消招生时的面试,生物工程退出试验班专业目录。
2017级软件工程重回试验班,建筑学纳入试验班高考招生,在上海将除特定试点班外的工科全部纳入工科试验班。
2018级工科大平台推广到全校工科专业,专业预选后试验班被打散。
当我查阅《上海交通大学年鉴》的时候,翻阅到了一些试验班的新闻片段。现张贴如下:
……依托试点学院探索工科试验班类提前批招生新模式。……工科大平台面向全国12个省市招收了407名(含贫困专项定向招生21人)学生。共有八个学院的23个工科专业参与平台建设,专业预选前三志愿满足率达到98%。——《上海交通大学年鉴2015》
继续实施基于试点学院改革的工科大类提前批招生工作。在部分省(市)高考本科第一批次前投放理科计划,以“工科试验班类”为代码,采用综合评价方式招生,纳入到学校“工科创新人才培养平台”进行培养,为对大工程学科有强烈兴趣、具有创新和发展潜质的学生提供更多进入上海交大的机会。……2014级工科平台专业分流进展顺利,共有63名学生实现了二次专业选择。2015级工科平台专业预选**前三志愿满足率达到了97.1%**。——《上海交通大学年鉴2016》
工科平台第一届学生已圆满结束平台学习期,2015级工科平台专业分流进展顺利,共有56名学生实现了二次专业选择,成功转专业比例达61%。在前两年运行成效显著的基础上,全校共有六个学院的19个专业参与工科平台建设,面向14个省市招收了735名学生,2016级工科平台专业预选前三志愿满足率达到了97.1%。——《上海交通大学年鉴2017》
2017级工科平台和生环平台专业分流进展顺利,2017级工科平台专业预选**前三志愿满足率达到98.64%。生环平台达到88.84%,二次分流成功转专业比例分别为70%和63%**。——《上海交通大学年鉴2018》
将上述数据和其他公开数据整理之后,成表如下:

这里需要解释一下“前三志愿满足率”。工科平台在进校第一个月结束的时候进行专业预选(注意这里不叫专业分流),需要按照顺序填写六个学院的志愿。按照2018级各学院预选人数表,假设所有人的前三志愿都是“电-机-船”(顺序无关),那么前三志愿满足率就有(524+268+150)/1122=83.96%。

关于转专业,2016级及以前的资料可以参见我的知乎回答。
2017上海交通大学工科大平台大一新生面临分流,学长学姐学的是什么专业,有什么建议吗?
2017级转专业结果可以参见下面的链接。
【专业分流】上海交通大学关于2017级工科平台专业分流结果公示的通知 - 上海交通大学 工科平台
2017级转入转出表

2017级转入专业录取名次区间表(不对数据真实性负责)

关于工科平台和非工科平台的对比,可以参见《上海交通大学2017-2018学年本科教学质量报告》。
2018年,工科平台首届毕业生毕业,学校对首届平台学生进行了学业跟踪调查,结果显示,①平台学生在学习成绩、知识层面上,整体水平和末端水平都较面上学生优异。②平台学生7种学习能力增长值均较面上工科学生大,特别是平台学生在工程设计能力、工程实践能力、集成创新能力的增长显著。受访学生中具有创新意识的平台学生比例明显高于面上学生,约为后者的三倍。③平台学生在5个方面学习素养的同期增长均优于面上学生。④学生普遍反映,通过平台的学习,具备了广阔的知识面,为后续专业学习、深造及就业提供了良好的知识储备;平台科学的课程体系设置,增强了学生的学习能力,调动了学生的学习主动性;平台的培养模式,扩大了学生的交际圈,不同专业同学可进行知识互补,学学相长。⑤工科平台学生平均GPA高于面上学生;出国深造和在国内深造的比例接近全部工科平台学生的三分之二,略高于非工科平台学生,学生培养了专业兴趣,保持了浓厚的继续深造势头。
本文提及资料来源:
上海交通大学2017-2018学年本科教学质量报告 - 本科教学质量报告 - 上海交通大学信息公开网
上海交通大学年鉴